Mô hình AI rẻ tiền đáng ngạc nhiên của Deepseek thách thức những người khổng lồ trong ngành. Công ty tuyên bố đã đào tạo mạng lưới thần kinh Deepseek V3 mạnh mẽ của mình chỉ với 6 triệu đô la sử dụng 2048 GPU, vượt qua đáng kể các đối thủ cạnh tranh. Tuy nhiên, con số này chỉ phản ánh chi phí GPU trước khi đào tạo, bỏ qua nghiên cứu đáng kể, sàng lọc, xử lý dữ liệu và chi phí cơ sở hạ tầng.
 Hình ảnh: Obligame.com
Hình ảnh: Obligame.com
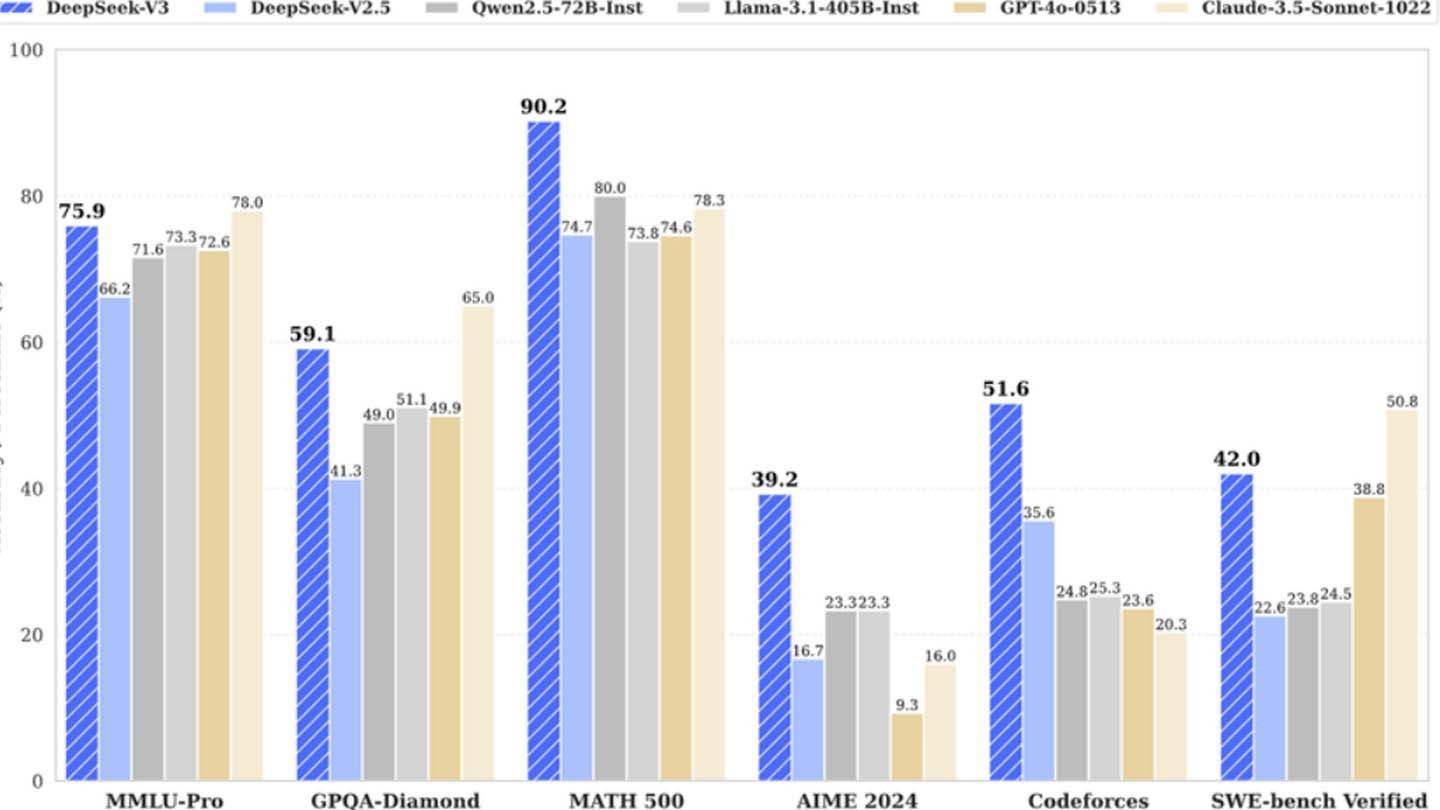
DeepSeek V3 tận dụng các công nghệ sáng tạo: Dự đoán đa điểm (MTP) để cải thiện độ chính xác và hiệu quả; Hỗn hợp các chuyên gia (MOE) , sử dụng 256 mạng thần kinh (tám hoạt động trên mỗi mã thông báo); và sự chú ý tiềm ẩn đa đầu (MLA) để tập trung vào các yếu tố câu quan trọng. Những tiến bộ này đóng góp cho hiệu suất cạnh tranh của mô hình.
 Hình ảnh: Obligame.com
Hình ảnh: Obligame.com
Trái ngược với các tuyên bố ban đầu, Semianalysis cho thấy cơ sở hạ tầng khổng lồ của Deepseek: khoảng 50.000 GPU phễu NVIDIA, bao gồm H800, H100 và H20, trải rộng trên nhiều trung tâm dữ liệu. Tổng đầu tư máy chủ được ước tính là 1,6 tỷ đô la, với chi phí hoạt động đạt 944 triệu đô la. Mặc dù vậy, Deepseek, một công ty con của High Flyer, một quỹ phòng hộ của Trung Quốc, duy trì sự độc lập và tự tài trợ, thúc đẩy sự nhanh nhẹn và đổi mới nhanh chóng.
 Hình ảnh: Obligame.com
Hình ảnh: Obligame.com
Thành công của công ty cũng xuất phát từ việc thu hút tài năng hàng đầu, với một số nhà nghiên cứu kiếm được hơn 1,3 triệu đô la hàng năm. Điều này, cùng với cấu trúc nạc của nó, cho phép thực hiện hiệu quả các tiến bộ AI. Tổng đầu tư vào phát triển AI vượt quá 500 triệu đô la.
 Hình ảnh: Obligame.com
Hình ảnh: Obligame.com
Trong khi câu chuyện "thân thiện với ngân sách" của Deepseek được cho là quá cường điệu, lợi thế cạnh tranh của nó là không thể phủ nhận, đặc biệt khi so sánh với 100 triệu đô la được báo cáo cho việc đào tạo ChATGPT4O, so với 5 triệu đô la của Deepseek cho R1. Trường hợp nhấn mạnh tiềm năng cho các công ty AI độc lập, được tài trợ tốt để thách thức người chơi đã thành lập, mặc dù đầu tư đáng kể vẫn là một yếu tố quan trọng.







